# Full Replication (formerly: Disaster recovery)
Full Replication (FR) encompasses all the ways to recover after losing hosts or storage repositories.
In this guide we'll only see the technical aspect of DR, which is a small part of this vast topic.
# Best practices
We strongly encourage you to read some literature on this topic. Basically, you should be able to recover from a major disaster within an appropriate amount of time and minimal acceptable data loss.
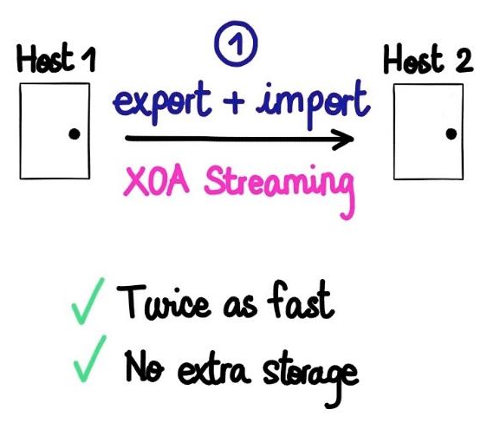
To avoid a potentially very long import process (restoring all your backup VMs), we implemented a streaming feature. Streaming allows exporting and importing at the same time (opens new window).
The goal is to have your DR VMs ready to boot on a dedicated host. This also provides a way to check if you export was successful (if the VM boots).
# Schedule a DR task
Planning a DR task is very similar to planning a backup or a snapshot. The only difference is that you select a storage destination.
You DR VMs will be visible "on the other side" as soon the task is done.
# Retention
Retention, or depth, applies to the VM name. If you change the VM name for any reason, it won't be rotated anymore. This way, you can play with your DR VM without the fear of losing it.
Also, by default, the DR VM will have a "Disaster Recovery" tag.
WARNING
A higher retention number will lead to huge space occupation on your SR.
# Network conflicts
If you boot a copy of your production VM, be careful: if they share the same static IP, you'll have troubles.
A good way to avoid this kind of problem is to remove the network interface on the DR VM and check if the export is correctly done.
WARNING
For each DR replicated VM, we add "start" as a blocked operation, meaning even VMs with "Auto power on" enabled will not be started on your DR destination if it reboots.