XenServer hyperconverged with XOSAN

This is the second blog post related to make XenServer hyperconverged in a simple way (check the previous link if you missed it!)
Today, we'll see how the main replication mode will work. A next post will explain about tiering (not planned for now, but very likely this year).
Current storage choices in XenServer
In the current XenServer storage paradigm, you can:
- store locally
- store in a shared storage repository (SR)
Both got pros and cons (this is a rough example but still):
| Local SR | Shared SR | |
|---|---|---|
| Speed | great (local hardware limit) | average to good (eg: network limits) |
| Data security | none | better (depends of your SR) |
| XS High availability | impossible | possible |
| Cost | cheap | dedicated hardware, can be expensive |
| Scalability | good (just add local disks and/or hosts) | bad (or not cheap) |
To workaround this situation, you can use both techniques, but it's a kind of a manual thing to manage.
So, what do we want? We need a solution which is:
- fast (at least, not slow)
- secure (losing one host won't destroy data)
- HA compatible (native XenServer HA)
- cheap (no extra/dedicated hardware to buy)
- scalable (just by adding hosts in my pool)
Solutions
That's why we started to think here at Xen Orchestra. Why not providing more than an UI to administrate, a backup solution and a cloud tool? Why not having an awesome stack and keep things easy to use?
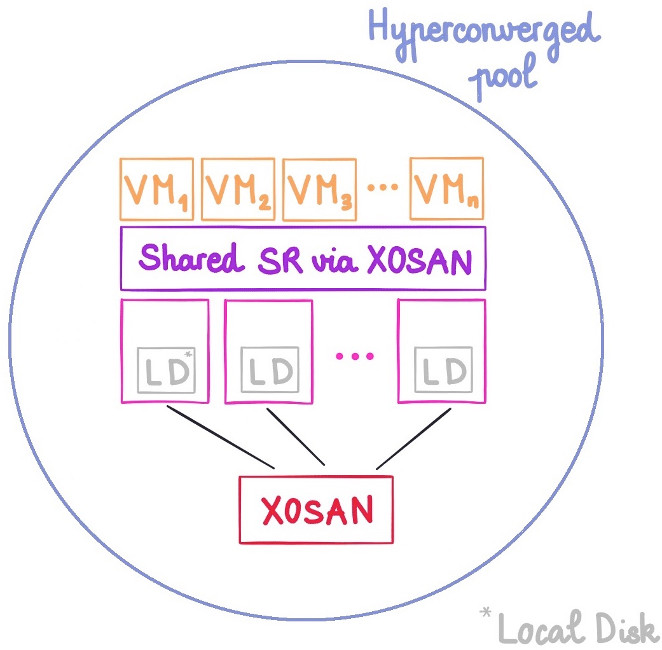
So we started to work on "XOSAN", to unify compute and storage!
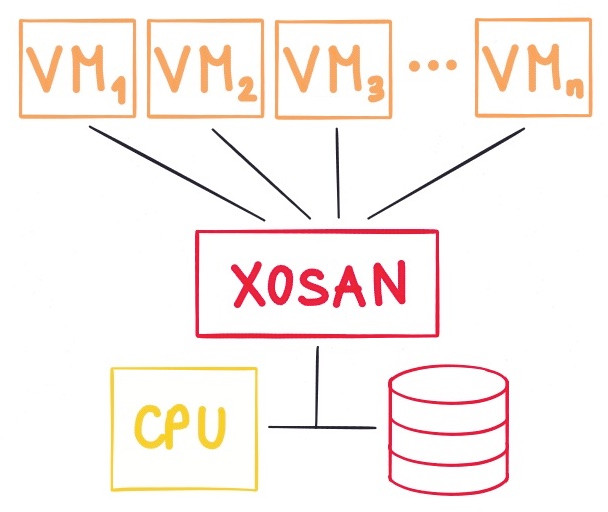
Replication?
Obviously, the initial blog post on XenServer hyperconverged was on a very small setup (2 nodes) replicated. But on a 10 nodes setup, this solution is:
- still fast
- still secure (you can lost all your hosts minus 1)
- HA compatible
- NOT cheap (waste a LOT of space)
- NOT scalable at all
Indeed, replicating on more than 1 hosts will give a lot of overhead. Eg, if you have 12 hosts with a 500GB SSD each, you don't want to replicate data on every node. Well, this is very safe but you can only use 500GB of disk space.
So what can we do? We need something better!
Erasure code to the rescue
Let's take our previous scenario: 12x hosts in the same pool, with a free 500GB SSD drive in each.
Total space combined is 6TB. It means, if you use local storage on each host, you can use 6TB of space for your VMs (if you can fill each 500GB drive). But if you lose 1 host, all the data on it are just… gone forever!
And what about replication? 500GB on 6TB means 5.5TB wasted (ouch, but you can lose all but one host, which is an ultra resilient pool!). Not good.
This is where erasure code mode come to the rescue: this mode allows you to choose how many host you can lose without actually losing your data.
- "Erasure 2" will mean I can lose 2 hosts without any problem (by losing I mean fully destroyed and unrecoverable)
- "Erasure n" will allow n hosts lost without anything going bad.
Let's re-use our example pool with 12 hosts and their 500GB SSD drive:
| Total space available | Space overhead | Tolerated max failures | |
|---|---|---|---|
| Local Storage | 6000GB | 0% | 0 |
| Replication | 500GB | 92% | 11 |
| Erasure 2 | 5000GB | 16% | 2 |
| Erasure 4 | 4000GB | 33% | 4 |
As you can see, this mode is really useful: it combines a really small space overhead AND security/resiliency on your data.
Which mode to choose in this example? Well, it's up to you! 2 failures tolerance is already good, and you'll have 5TB in your storage, which is pretty nice!
Scalability
Is it scalable? Yes, absolutely. Even better: 12 nodes will be faster than 3, because each piece of data will be accessed on different hosts (depending on the replication level and your network speed).
Obviously, we'll run benchmark in multiples situations to validate that claim.
A quick benchmark
Remember the first replication benchmark on 2 hosts? Now I got a third node, and I can use erasure mode with 1 failure possible.
In my case, I got 3x SSDs with 60GB available on each. So with "Erasure 1" mode, it means I got 120GB available in total, and if one host is down, that's OK. It's the same (cheap) hardware and (cheap) network:
| ZFS NAS | XOSAN Erasure 1 | diff | |
|---|---|---|---|
| Sequential reads | 122 MB/s | 172 MB/s | +40% |
| 4K reads | 14 MB/s | 24 MB/s | +70% |
| Sequential writes | 106 MB/s | 72 MB/s | -32% |
| 4k writes | 8 MB/s | 13 MB/s | +60% |
The only thing that's slower is sequential write speed. This makes sense, because of the extra computing power needed to send data on all 3 nodes at the same time.
And it's not bad at all, because 3 nodes is the "worst" setup possible: remember, more nodes, better performances! Also the 1 gig network could be a bottleneck, we'll investigate on a 10 gig net to check if it changes something.
Updates: check the numbers on a 10GiB network: https://xen-orchestra.com/blog/xosan-with-10gb-link-on-xenserver/