Understand XenServer VM High availability
A simple how-to about XenServer HA.


This article in a introduction to the VM HA mechanism in XenServer.
Implementing VM High availability is a real challenge: first because you need to reliably detect when a server has really failed to avoid unpredictable behavior. But that's not the only one.
If you lose the network link but not the shared storage, how to ensure you will not write simultaneously on the storage and thus corrupt all your data?
That's why XenServer is an awesome product (as its API, the XAPI): it handles flawlessly that kind of stuff. We'll see how to protect your precious VM in multiple cases, and we'll illustrate that with real examples.
How it works
The pool concept allows hosts to exchange their data and status:
- if you lose a host, it will be detected by the pool master.
- if you lose the master, another host will take over the master role automatically.
To be sure a host is really unreachable, HA in XenServer uses multiple heartbeat mechanisms. As you saw in the introduction, just checking the network isn't enough: what about the storage? That's why there is also a specific heartbeat for shared storage between hosts in a pool. In fact, each host regularly write some blocks in a dedicated VDI. That's the principle of the Dead man switch. This concept is important, and it explains why you need to configure HA with a shared storage (iSCSI, Fiber Channel or NFS) to avoid simultaneous writing in a VM disk.
Here is the possibles cases and their answers:
- lost both network and storage heartbeat: host is considered unreachable, HA plan is started
- lost storage but not network: if the host can contact majority of pool members, it can stay alive. Indeed, in this scenario, there is no harm for the data (can't write to the VM disks). If the host is alone, i.e can't contact any other host or less than the majority, it decides to go for a reboot procedure.
- lost network but not storage (worst case!): the host considers itself as problematic, and start a reboot procedure (hard poweroff and restart). This fencing procedure guarantee the sanity of your data.
Configuration
In this example, we'll have a pool Lab pool with 2 hosts, lab 1 and lab 2.
Prepare the pool
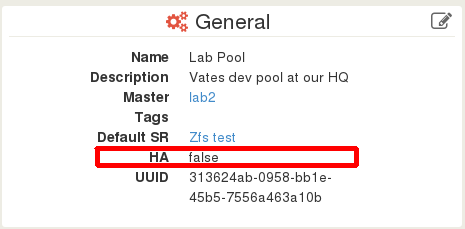
You can check if your pool have HA enable or not. In Xen Orchestra, you just have to click on a pool name in order to go on a Pool view. The General pane displays the HA status, in this case, HA is disabled:
You can enable it with this xe CLI command:
$ xe pool-ha-enable heartbeat-sr-uuids=<SR_UUID>
Remember that you need to use a shared SR.
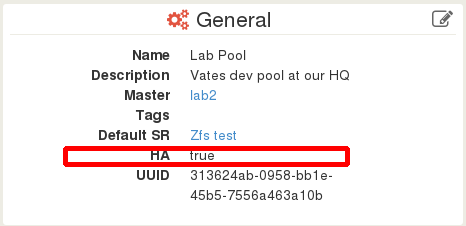
Now, it will display true for HA:
Maximum host failure number
Now, you have to think: how many host failures you can tolerate before running out of options? For 2 hosts in a Pool, the answer is pretty simple: 1 is the maximum number. Why? Well, after loosing one host, it will be impossible to ensure a HA policy of the last one also fails.
This value can be computed by XenServer, and in our example case:
$ xe pool-ha-compute-max-host-failures-to-tolerate
1
But it could be also 0. Because even if you lose 1 host, is there not enough RAM to boot the HA VM on the last one? If not, you can't ensure their survival. If you want to set the number yourself, you can do it with this command:
$ xe pool-param-set ha-host-failures-to-tolerate=1 uuid=<Pool_UUID>
When you have more hosts failed that this number, a system alert is raised: you are in a over-commitment situation.
Configure a VM for HA
This is pretty straightforward with Xen Orchestra. Go on your VM page, then edit the General panel: you just have to tick the HA checkbox and click on Save.
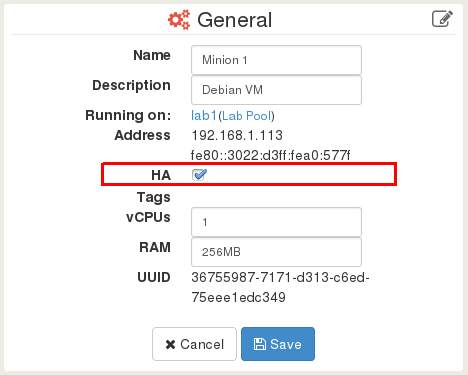
Note: This feature is coming for the next release, but it's already working in our lab.
You can also do that configuration with xe CLI:
$ xe vm-param-set uuid=<VM_UUID> ha-restart-priority=restart
Behavior
Halting the VM
If you decide to shutdown the VM with Xen Orchestra, XenCenter or xe, the VM will be stopped normally, because XenServer knows that's what you want.
But if you halt it directly in the guest OS (via the console or in SSH), XenServer is NOT aware of what's going on. For the system, it seems the VM is down and that's an anomaly. So, the VM will be started automatically!. This behavior prevent an operator to shutdown the system and leave the VM unavailable for a long time.
Host failure
We'll see 3 different scenarios on the host lab1:
- physically "hard" shutdown the server
- physically remove the storage connection
- physically remove the network connection
lab1 is not the Pool Master, but the results would be the same (just longer to test because of time to the other host becoming the master itself).
Let's stay in our example of 2 hosts in a single pool. I configured the VM Minion 1 for HA, and this VM is running on the host lab1.
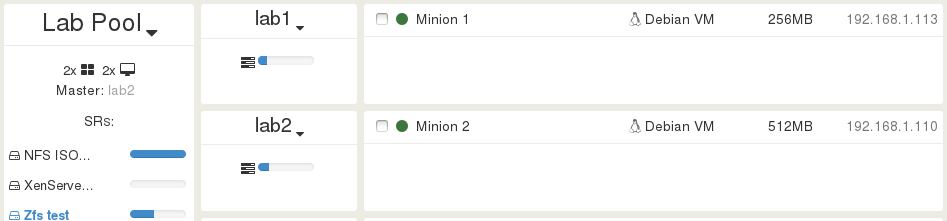
After each test, Minion 1 go back to lab1 to start in the exact same conditions.
Pull the power plug
Now, I decide to pull the plug for my host lab1 (true story, it's a Lab after all). This is exactly where is my VM. After sometimes (when XAPI detect and report the lost of the host), we can see that lab1 is reported as Halted. In the same time, the VM Minion 1 is booted on the other host running, lab 2:
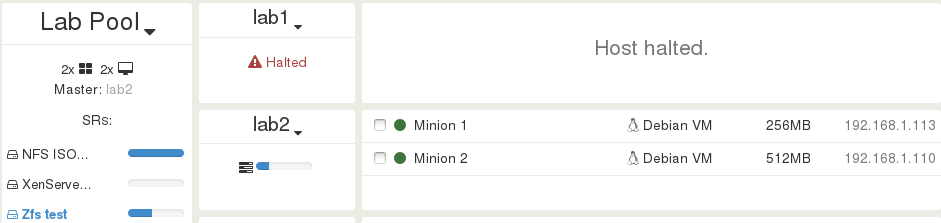
Congrats! Despite the total loss of a host, you have nothing to do for the protected VM!
I decide to re-plug the host lab1. Just after it booted, it's back in the business with no VM running on it, which is perfectly normal:
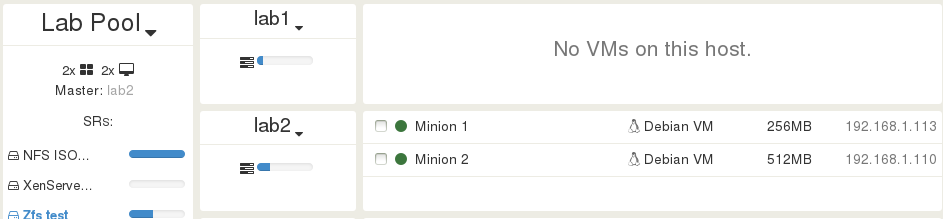
Pull the storage cable
Ok, so let's try another scenario. This time, I will unplug the iSCSI link on lab1, despite Minion 1 is running on it.
So? Minion 1 lost access to its disks ad after some time, lab1 saw it can't access the heartbeat disk. Fencing protection is activated! The machine is rebooted, and after that, any xe CLI command on this host will give you that message:
The host could not join the liveset because the HA daemon could not access the heartbeat disk.
Immediatly after fencing, Minion 1 will be booted on the other host:
Note: lab1 is not physically halted, you can access it through SSH. But from the XAPI point of view, it's dead. Now, let's try to re-plug the ethernet cable... and just wait! Everything will back to normal:
Pull the network cable
Finally, the worst case: leaving the storage operational but "cut" the (management) network interface. Same procedure: unplug physically the cable, and wait... Because lab1 can't contact any other host of the pool (in this case, lab2), it decides to start the fencing procedure. The result is exaclty the same as the previous test. It's gone for the pool master, displayed as "Halted" until we re-plug the cable.
Conclusion
As you can see, XenServer provides a powerful solution for high availability. We'll see more possibilities in a future article (about the restart policy and boot order). Comments are welcome if you have any questions or suggestions.
Oh, and if you want to take a look at Xen Orchestra features in videos, follow the link ;)