XenServer and XCP-ng coalesce detection
Discover how Xen Orchestra protect your XenServer and XCP-ng infrastructure.


We are proud to present a new feature that will help a lot to improve current XenServer backups with Xen Orchestra, but also to notify you when a storage repository is coalescing its disks.
A backup problem
The initial work on this was triggered by 2 symptoms. Some people could have:
The Snapshot Chain is too LongSR_BACKEND_FAILURE_44 (insufficient space)
But it was all related to the same cause. Before digging on this, let's go back to how a snapshot works.
Quick recap on snapshots
Don't forget to take a look of this great Citrix resource on how snapshots are working.
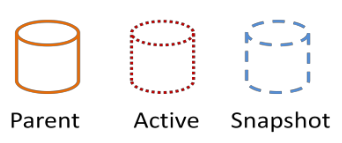
When you make a snapshot, a "base copy" is created (in read only), the "active" disk will live its own life, same for the freshly created snapshot. Example here: A is the parent, B the current/active disk and C is the snapshot:
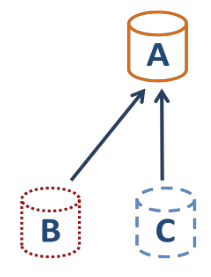
That's OK. But what about creating a new snapshot on B after some data are written?
You got this:
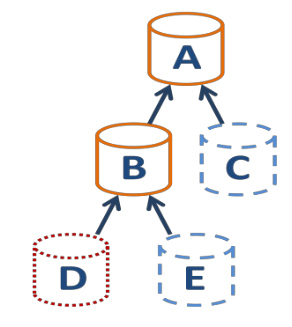
Backup scenario
When you make XO backup on regular basis, we'll remove old/unused snapshots. So in our case, C will disappear. And without this snapshot, XenServer will coalesce A and B:
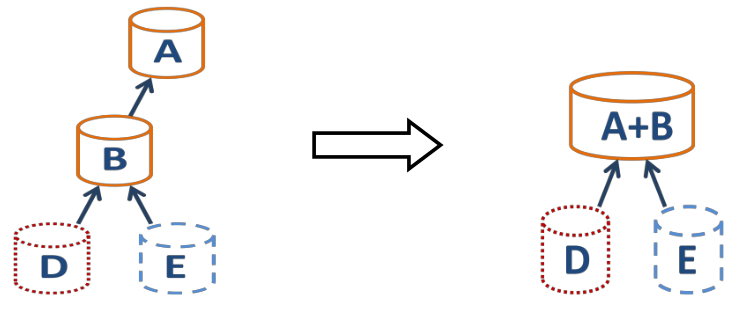
This process will take some time to finish (especially if you VM stays up and worst if you have a lot of writes on its disks).
You start to get the point?
Faster than coalescing speed
What about creating snapshot (ie call backup jobs) faster than XenServer can coalesce? Well, the chain will continue to grow. And more you have disks to merge, longer it will take.
You will hit a barrier, 2 options here:
- if your VM disks are small enough, you could reach the max chain length (30)
- if you VM disks are big, you'll hit the SR space limit before.
Sounds familiar right? But, how to avoid this case? Hard to verify yourself if your SR can keep up the pace…
Solution
We managed something to avoid taking a new backup if the coalesce is still not finished! In fact, we are able now to detect this behavior and to prevent new snapshot creation. You'll be also notified (job fail) with your configured backup reports. So it won't clog your SR with a mountain of snapshots that will require hours (days!) to finish.
In other words, you are now protected: you can't backup faster than your resources could allow. During the next job call, if the chain is correct, the backup will work.
Going further
But now we can avoid to go directly toward a wall, we could go even further: having this info in "health" section of Xen Orchestra that will report chains that are coalescing, and on which storage. This way, for any reasons (manual snapshots done too often), you will know it.