Full stack power
This is the story on a epic bug hunt. Our XCP-ng knowledge demonstrates that we could solve a nasty XenServer regression that critically impacted Xen Orchestra backups. And this was solved in a very short time frame.


This is the story on a epic bug hunt. Our XCP-ng knowledge demonstrates that we could solve a nasty XenServer regression that critically impacted Xen Orchestra backups. And this was solved in a very short time frame.
When you are able to master the full stack, from the hypervisor to the backup solution, no issue can stand against XCP-ng+XOA combo!
Update: we validated a "definitive" fix with Citrix devs, and it's now merged!
VDI I/O error
It all started with more and more people complaining about VDI I/O Error when doing backups with Xen Orchestra. The common thing between all those people was XenServer 7.5. But we couldn't reproduce it easily in our lab.
So we started digging to understand what could be the issue, obviously something introduced in XenServer 7.5. Immediately, we opened an issue on Citrix XenServer bug tracker. But our needs aren't obviously completely aligned with Citrix, which doesn't seems to do extensive testing on VDI export, used in Xen Orchestra to make backups. That's why we couldn't wait weeks or months to get a resolution. We had to investigate ourselves.
Streams
First, let's do a quick recap on a backup works. We use NodeJS streams. Basically, we:
- fetch the content from a XCP/XS host (input stream)
- write the content on the "remote", eg NFS share (output stream).
As you can imagine, sometimes, the "remote" can be slower than the content export. In this case, there is what's called backpressure.
Here is an exemple of a bottleneck in the middle:
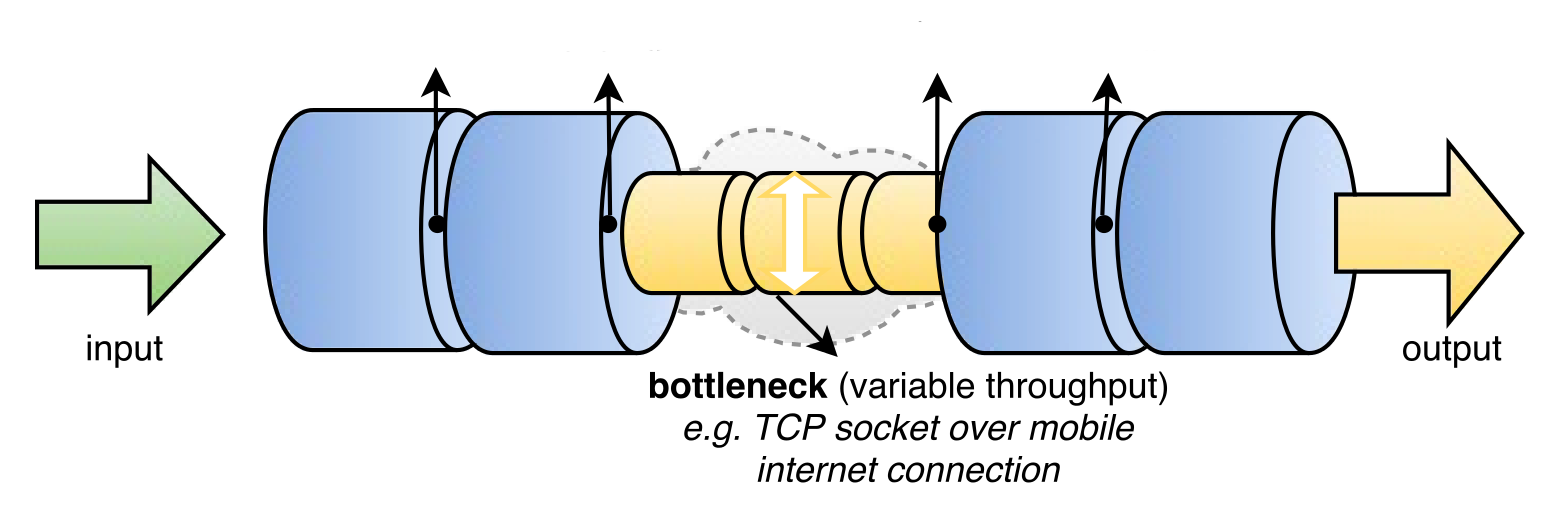
Basically, this can cause Xen Orchestra to pause fetching data on XenServer. Which wasn't a problem before. But now, it seems as soon the data is not fetched for few seconds, it stops the export with a VDI I/O error. And you got a failed backup job.
First idea: XO workaround
We tried to implement a workaround in Xen Orchestra, but it was overcomplicated and despite it working for some people, it wasn't the case for everyone. Indeed, you have to choose between more buffer inside XO during the transfer, but also having potential RAM issues if backupressure never ends.
And the side effects could be problematic for previous version of XenServer/XCP. So we had to fix the issue in XenServer/XCP-ng directly!
Investigating vhd-tool
In XenServer/XCP, the library the do the HTTP handler for exporting VHD data is vhd-tool. So, since 7.4 was released, we examined each commit on GitHub, to find a potential culprit.
And a commit caught our attention: Catch EAGAIN from sendfile and retry .
EAGAIN? Sounds familiar. After rechecking the /var/log/xensource.log, we found this:
VDI Export R:24d4f0381f9c|vhd_tool_wrapper] vhd-tool failed, returning VDI_IO_ERROR
VDI Export R:24d4f0381f9c|vhd_tool_wrapper] vhd-tool output: vhd-tool: internal error, uncaught exception:
Unix.Unix_error(Unix.EAGAIN, "sendfile", "")
Raised at file "src/core/lwt.ml", line 3008, characters 20-29
Called from file "src/unix/lwt_main.ml", line 42, characters 8-18
Called from file "src/impl.ml", line 811, characters 4-23
Called from file "src/cmdliner_term.ml", line 27, characters 19-24
Called from file "src/cmdliner.ml", line 27, characters 27-34
Called from file "src/cmdliner.ml", line 106, characters 32-39
Basically, the new code will try 20 times if EAGAIN is triggered (a system call telling "we couldn't write now"), waiting 100ms every loop, which is 2 seconds tops. Then failing with VDI I/O error. Obviously, this is not enough is a lot of cases, eg a busy network or a slow NFS share where you store your backups.
A quick but working fix
So the idea was to make a test by raising considerably the number of tries before giving up:
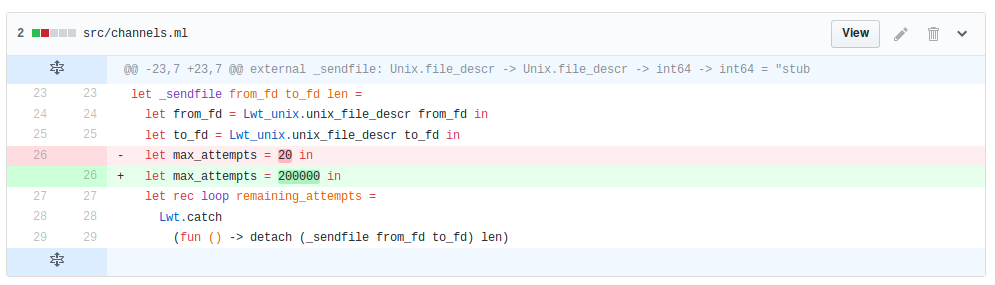
We offered the solution direclty to Citrix via GitHub, helping them to get a fix very quickly without even having to do it. The Pull request can be improved if necessary. We hope they could push a fix quickly into XenServer.
Because we know how to build packages for XS/XCP-ng, we were able to build a new VHD-tool RPM package and deploy it on our XCP-ng 7.5 RC1 hosts. Guess what? It worked perfectly, even of very slow NFS share, even by shutting down NFS for few seconds, and bringing back online then.
We decided to include the fixed VHD-tool version directly in XCP-ng 7.5, this way people won't have to wait to get Xen Orchestra backup to work again.
The fix is not very elegant, but it's harmless, so we'll continue to assist Citrix if they want to implement a better solution.
Update: final fix
Good news! We validated a "definitive" fix with Citrix devs. It's far more elegant:
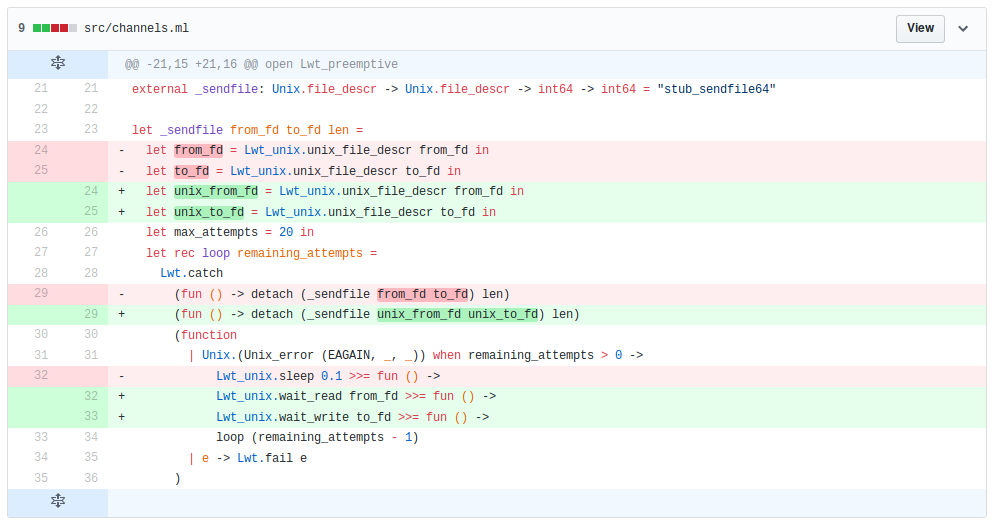
This fix removed the need of sleep in the loop, and the PR is now merged! This improved version is also already in XCP-ng 7.5 :)
XCP-ng 7.5 Release Candidate
Want to test our latest XCP-ng 7.5? It's available now as a first release candidate, see the post on our forum! and our blog post announcement. It's not just embedding our VDI I/O error fix, but also ZFS experimental support and much more!
