Evolution of our cache system for VM restore
Learn how we improved our system to fetch existing VM backup information, in order to display everything fast inside your Xen Orchestra web UI.


In any software, there's always a lot more happening behind the scenes than you can actually see. And there's also a time when you need to optimize internal things to improve visible performance. Today, we'll show you how we managed to drastically reduce the loading time from your "Restore backup" view, even in cases where you have a lot of VM backups stored.
💾 Backup Repository
A backup repository ("BR", also called "remote" in Xen Orchestra) is the place where we store all the VM backups you perform (full/standard or delta). Usually, this repository is a network share, likely behind NFS or SMB protocol.
One of our goals with Xen Orchestra was the ability to keep the backup data AND metadata fully self-contained and separate from your Xen Orchestra. This way, if you even lose your Xen Orchestra VM and/or even all your physical XCP-ng hosts, you can still restore everything by deploying a new XO on your fresh hardware from scratch, find all your existing backups on the BR, restore and get back on your feet!
So, what's the issue then ? Well, it starts to be slow to parse and read when the number of metadata files is big. Let's see why.
↔️ Query all available backups
When you enter into the "Backup" view, then the "Restore" tab, XO will list for you all the available backups to restore (for each VM, with the number of available backups per VM). Users with medium/large sized infrastructure started to have hundreds (and even more sometimes) backups. And we discovered it took time to load that screen.
Without any cache
This is what we had before XOA 5.71: when we listed all available backups, the requests behind the scenes were pretty simple:
- read the content of the
xo-vm-backups/folder on all available Backup Repositories (BR) - then, inside each BR, read all subfolders,
xo-vm-backups/* - finally, read all the metadata info of each backup for each VM,
xo-vm-backups/*/*.json
Even if those JSON files aren't big in size, remember that the BR is stored in a network share. Each file to read will take a network roundtrip: even a latency of 10ms, multiplied by the number of VMs and each backup (retention), you start to have more than a few seconds to load everything. And clearly, this had to happen each time you were navigating to this restore view! As you can see, it doesn't scale well.
Adding a first cache system
That's why we decided to add a new cache system, to avoid unnecessary requests on files that weren't modified:
- VM cache was generated on demand when listing the backups
- VM cache was deleted on backup creation/deletion
In order to avoid listing and loading a LOT of different files (read folder + read file), we decided to add a "static" file with an obvious path and name so we don't have to list a folder to find it: xo-vm-backups/*/cache.json.gz. As you can see, the JSON is also compressed to reduce the amount of data stored AND going over the network, adding another benefit to the overall improvement.
And it was fine… for a while. Our main target, medium/large sized infrastructure users, had a lot of backup creation and deletion activity invalidating the cache very often, making it almost useless to them.
And at this point, we decided to improve further that cache system.
Going even faster
This new cache implementation is available since XO 5.75. This time, we decide to… update the cache directly! (at each backup creation/deletion)
It might sound subtle, but in fact, this changed everything: the new cache is always available and up-to-date. Obviously, we had to also get some cache coherency checks: when a backup is finished, we have a "clean VM" set of instructions we use to verify if the cache is consistent or not. If not, then we remove it. Luckily, there's no good reason for this to happen!
🎯 Result and conclusion
To sum up, the new cache system is a lot more efficient, but allows direct modification (ie: no invalidation in a normal run), serving compressed files at a predictable path.
The result? Let's compare before and after the cache, on a modest backup repository: 22x VMs with a average retention around 45. This already means 1000 JSON files to list, read and parse.
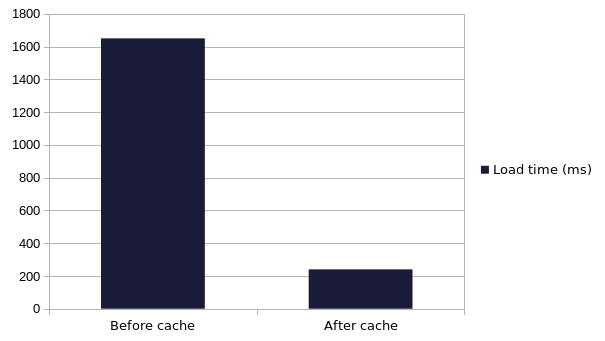
It's pretty simple: we improved the performance by dividing the load time by 8. Not bad 😎 And remember: this is only on a relatively small backup repository, on a pretty fast network. The gap is even bigger on larger and/or slower infrastructures.
We hope you like this kind of "behind the scenes" content, let us know about your reaction on our community forum!