Better, faster and stronger backups
After spending some times on improving backup code, we'll deliver it for 5.17 version. Changes are very important and lay the foundation of exciting new features. Let's see why it's a big leap ahead!


After spending some times on improving backup code, we'll deliver it for 5.17 version (next Friday!). Changes are very important and lay the foundation of exciting new features. Let's see why it's a big leap ahead!
Better 👑
"Better" here means more new features! We got a new UI to make a backup. You'll start now by choosing which VM to backup, then where, and finally how.
Multi-remote
In the step of choosing the destination of your backup, you'll have 2 possibilities:
- a remote (a place to store your backup, NFS/SMB/local)
- a SR (storage repository), to make Disaster Recovery or Continuous Replication
But you can select BOTH and do for example, a delta backup to store it AND a continous replication at once (or both basic backup and disaster recovery).

So, with one snapshot on the VM, data will be sent both in your remote and on the target XenServer storage. Yes, at once!
That's not it! You can also select multiple remotes (let's imagine "backup site A" and "backup site B")… or both multiple remotes and multiple SR in the same job. No excuses, your backups can be stored everywhere without anything more than two clicks :)
Obviously, data flowing through XOA can't be kept in memory, so due to "back pressure", backup speed can't be faster than the slowest destination (remote or SR).
Multi-schedule
In one job, you can choose to make the backup at various schedules. For example, you can now do, in the same one job, those schedules:
- a daily backup (at 3AM)
- a weekly backup (Sunday, at 6AM)
- a monthly backup (Friday at 1AM)

Cancelable
It's now possible to cancel a backup, for whatever reason. Also, a timeout will automatically cancel it for real (it wasn't the case before).
Faster 🚀
Concurrency
We have now a fine-grained concurrency management. It means we selected the best action to do in parallel, depending the type of backup you do. Let's see the changes made for delta backup!
Delta backup concurrency
You can do multiple things at once, but you need to be careful.
VDI exports
XenServer VDI export is not ultra fast: in fact, it's a big bottleneck. Basically, on a 1Gbit/s link, exporting one VDI in VHD format is around 30MiB/s. Pretty slow, right? But does it scale? If you export more VDI at once?
Here is a graph, with the average VDI export speed (per VDI) and the total export speed:
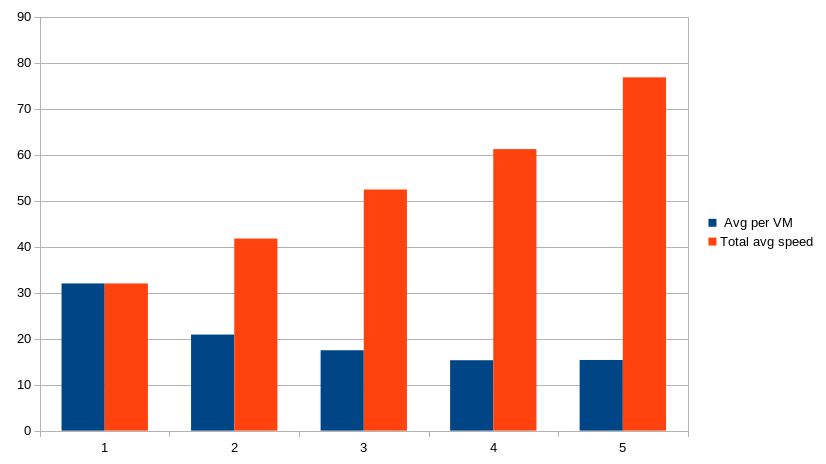
Exporting 1x VDI at +30MiB/s, but 2x at 20MiB/s each! It means you can double the total export speed just by using a concurreny at 2.
We can continue to scale and see that more VDI we export at once, more the total export speed is high.
That's why we extended the VDI export concurrency limit to 12 per pool (doing more isn't really faster).
Snapshots concurrency
On the other hand, doing multiple snapshots at once seems to cause issues in XenServer (probably "race conditions" related). So we decided to limit snapshot concurrency to… 1! This helps to get rid of XenServer race condition, without impacting backup speed in the end.
Delta merge process
If you know about continuous delta backup, you know that Xen Orchestra need to merge the oldest delta into the initial full, when the retention number is reached. And it was slow! On an NFS share, it was around 15MiB/s max on our test setup, due to a lot of open/close on the VHD file. Indeed, on a network filesystem, a lot of open/close cost a LOT due to latency. So we decided to make one open() at the start, and one close() call at the end.
Check the result on the merge speed:
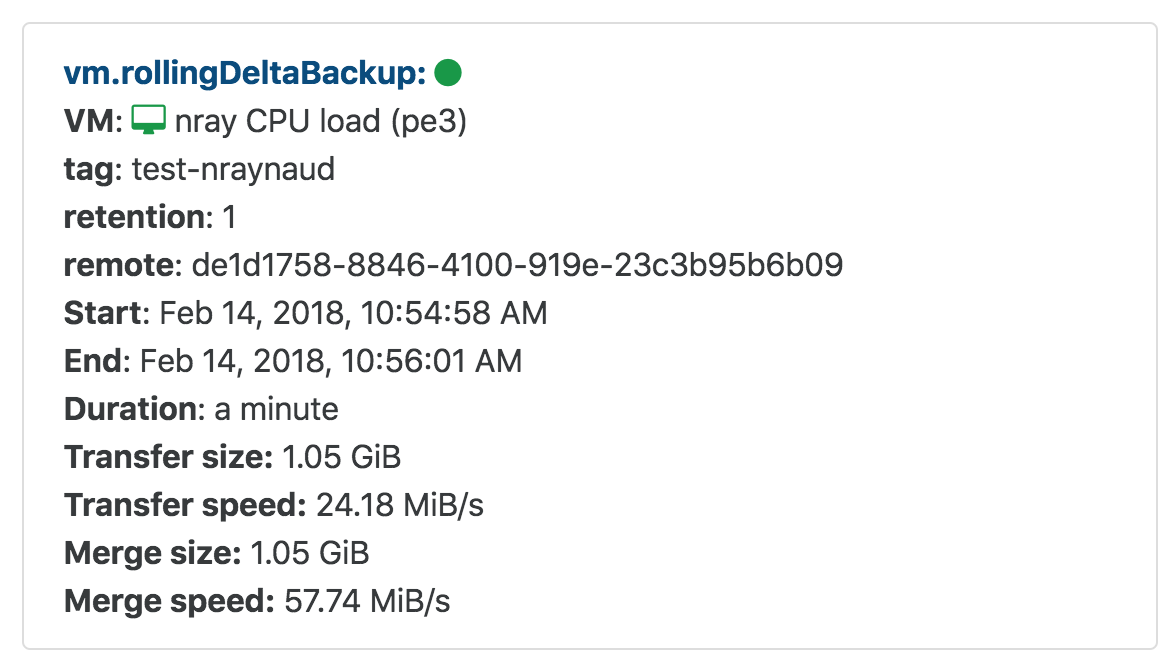
That's right: almost 60MiB/s, which is 4 times faster than before!
Stronger 👊
The hard part of doing a backup workflow, is when something doesn't work as expected. We improved overall resiliency. For example, you should be able to adapt/fix automatically those potential situations during a backup:
- host reboot
- toolstack restart
- XOA reboot/restart
- network loss
- reference snapshot removal (delta backup)
- merge failure (delta backup)
That's why we spent a lot of time dealing with the maximum number of issues. Now, we are able to detect the majority of problems and fail correctly (removing failed snapshots and/or temp file on the remote).
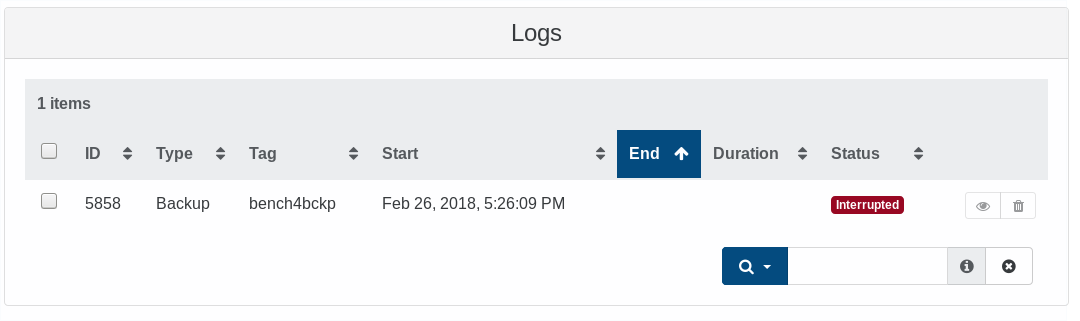
Also, logs are reporting "Interrupted" jobs correctly (it doesn't stay on "Pending" state):
Just a start 💡
And this is just a start. We'll continue to improve backup incrementally, from these solid foundations. Expect more and more cool features in the next months, still with those 3 words in mind: faster, better, stronger!
