DevBlog #8 - Improving backup performance in Xen Orchestra
Backup features are the most used tools in Xen Orchestra. Therefore, we are paying special attention to the performances we have and are constantly working to improve it. Today, we share our plans regarding the future.


One of the most important projects for the next few months in Xen Orchestra will be to improve the backup performance in our solution and to bring new tools for our users to improve their infrastructure.
First step - Identification
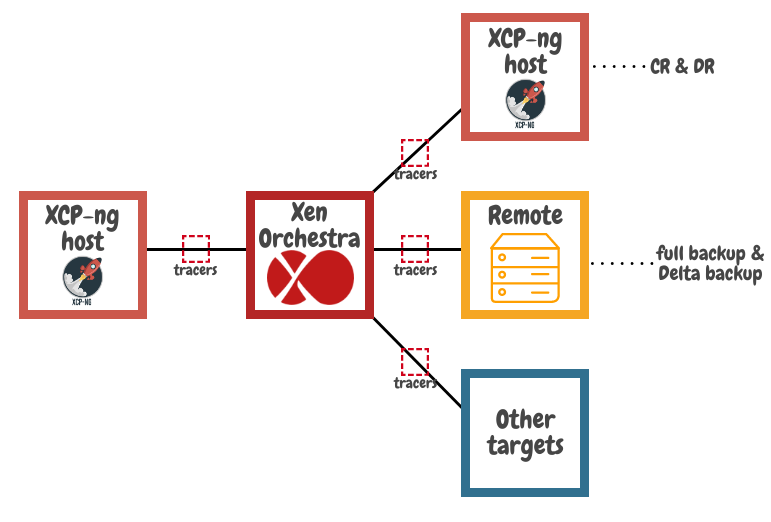
We have some ideas about what can be improved in our solution, but no certainty. This is the reason why the first step in our improvement process will be to integrate Stream probes (or "stream tracers").
The main job of these tracers will be to identify where the slowdowns are (XO itself? XCP-ng/Citrix Hypervisor export or import? I/O on the remote?)
These probes might bring far more than just identifying when Xen Orchestra is the limitation and help us to work on that, it can also bring new features to allow a user to visualize bottlenecks in their infrastructure (network, storage, XO proxy...) and bring corrective action. Maybe even in XCP-ng itself!
Improvements exploration
VHD merge in delta backups
Currently when a delta backup job reaches its retention time, we are merging the oldest delta VHD file with the Full VHD. The consequence of this mechanism is that each block of data in the VHD file is, first, read (downloaded) from the delta and then written (uploaded) to the full.
It's not completely optimal on a "remote" (here, a network share), because this action will use network and disks resources. Additionally, editing the full VHD directly can be slower with some Copy on Write (CoW) filesystems used in your remote (btrfs seems to be affected).
A way to avoid this process would be to "explode" the VHD itself, which means that each block of the VHD would have its own file. With this implementation, instead of merging the VHD block in the full VHD, we will simply have to rename the file and remap the full VHD metadata. This solution will surely improve the merge speed - but there is a big drawback.
Having a file for each datablock will generate a very large number of files (eg. for a full 2TiB disk, that will represent a little bit more than 2 Million files!). Consequently, this feature will only work with remotes supporting lots of files (btrfs, zfs and some others).
Another issue would be that it will no longer be possible to directly upload the full VHD file to XCP-ng/XenServer.
Of course for all the previous reasons, this feature would be something optional in Xen Orchestra, or at least useful to see the progress we can make with the VHD merge process.
New backup code
As a more general improvement, the whole backup code has been rewritten when we worked on the Xen Orchestra proxy. However, this newer and better code, (refactored, cleaner and simpler) is not yet the one used in Xen Orchestra itself.
In the near future, this code will become the main code used in Xen Orchestra.
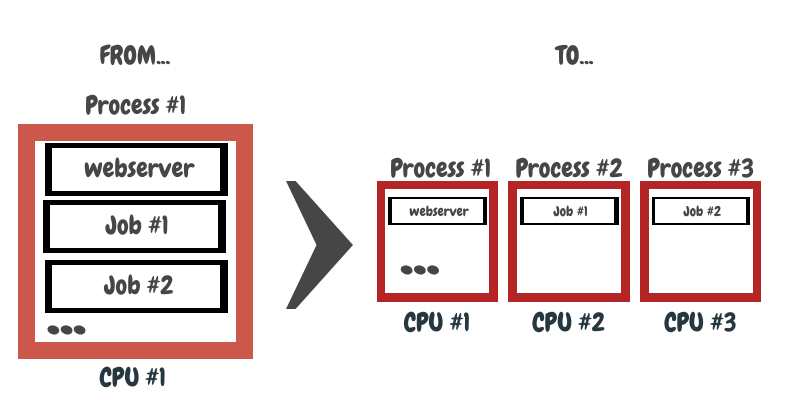
One job - One process
Another thing we already know is that currently, running a whole backup job will create a single process. This may create performance issues when it comes to very large backup jobs, with a lot of VMs to backup.
Splitting all the jobs into different processes for each should have multiple benefits:
- It will make XO more responsive
- A single process crashing will not stop everything
- Backup performance will be less CPU limited - a single process runs in a single CPU, but multiple processes means you can add vCPUs to get faster backups
Custom snapshot implementation
We are also thinking about a custom snapshot implementation allowing us to avoid snapshotting ignored disks (which is currently impossible, we are snapshotting them, and deleting them before the export).
It should improve the performance of the snapshot process and reduce the disk space required for the snapshot (especially for thick provisioned storage). A little drawback to this is that it won't be compatible anymore with quiesced snapshots (which is a deprecated feature in Citrix hypervisor anyway).
NBD implementation
This is the latest thing we are exploring. Instead of using the VHD format we are looking forward to completely changing the way backup works in Xen Orchestra and using block tracking instead of VHD.
This topic is particularly vast and will require a lot of experimentation first on our side, so we won't get deeper about this in this devblog, a dedicated one will come in the future. But clearly, it will be interesting to compare with the current VHD mechanism (in terms of speed for example).