Xen Orchestra 5.86
Take a look on our latest Xen Orchestra 5.86 release. On the menu: backup improvements, XO Lite and various changes.


Following our summer hiatus, we're excited to unveil the latest iteration of Xen Orchestra, in its version 5.86, now accessible to everyone. This month, we've enhanced various backup functionalities while exploring deduplication, and made significant strides in the ongoing development of both XOSTOR and XO Lite.
And here is the podcast format!
💾 Backup
Various improvements but also some exploration on potential gain related to deduplication!
Retry on write error on S3 backup
The S3 protocol became a de facto standard to store many things. The issue with that: many different S3-compatible providers are providing different error codes depending on the issue. The "standard" isn't really a standard when you have errors. This make the retry very difficult: we started by reading the actual error, but since there's hundreds (thousand likely) different providers with their own error code, it was not really reliable.
That's why we decided to be more aggressive on retry, regardless the details error code returned by your S3 provider. This will mitigate failures and provide a better reliability without restarting a whole backup job!
Parallelize merge worker
This new features enables parallel merging of multiple VMs within the merge worker, a feature designed specifically for high-performance BR (Backup Repositories). When you have fast SATA SSDs or NVMe drives, you might have faster merge when doing in parallel on multiple VM disks.
Exploring deduplication with ZFS
This month, we investigated backup deduplication with ZFS, examining its efficiency, potential challenges, and prerequisites in order to create our own in-house deduplication solutions.
Why using ZFS for deduplication?
Storing backups as VHD files doesn't work well with ZFS block-based deduplication: even identical backups might have different ZFS block alignments within the file, making deduplication inconsistent and generally not very effective.
Switching to block storage backup ensures that each 2MiB backup block contains exactly the same content. This approach works smoothly with ZFS deduplication. When you create two key (full) incremental backups, they only occupy as much space as one full backup, without significantly compromising reliability. If a block from the older backup is changed or corrupted externally, it's saved as a new block in the new key backup, ensuring the integrity of the backup chain.
The effectiveness of deduplication also depends on the duplication between your disks. You can check the duplication ratio using the ZFS tool zfs -S tank.
You can test this without actually enabling it on an existing backup repository. Here's a guide: Testing ZFS Deduplication.
Extra Note:
- Deduplication on ZFS consumes a significant amount of memory. If you don't have enough memory available, it will use disk space instead, but this can slow down performance. Our tests indicate that you need at least 1% of your disk's capacity in memory for efficient deduplication. That is 10GiB of memory per disk TiB
- Deduplication doesn't work with encrypted backups because encryption adds a unique identifier at the beginning of the file, making it completely different on disk. This doesn't apply to full backups.
What's coming next?
We'll explore testing on Btrfs, especially with bees, which claims to use only 0.1GB of storage per terabyte.
In the end, we're in the process of developing our own in-house deduplication method: we plan to make it available to users only if it proves to be notably more effective and easy to use than the currently existing approach, by knowing the structure of the data stored.
Exploring a fast path for backup
For now, the usual bottleneck in XO backup speed is on the host itself (XenServer/XCP-ng). Mostly because the program that exports the VM will make many conversions (VHD to raw to VHD). Our initial tests to simply bypass it and rely on a small Python PoC (far from being optimized) is giving very promising results, like around twice the backup speed.
We are working on a PoC to explore this more, while discussing with the upstream (XAPI project) about how to achieve similar speeds natively.
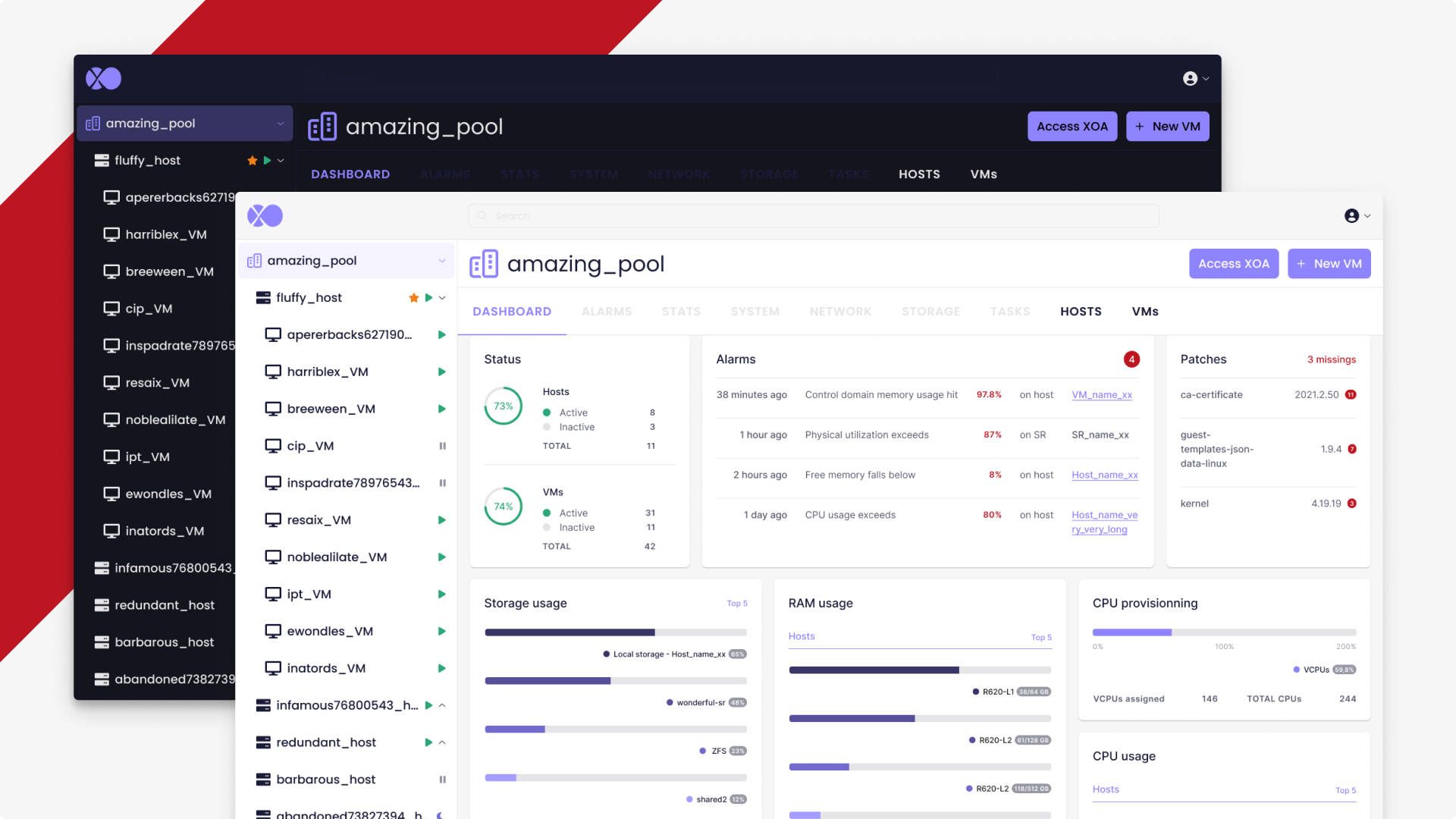
🔭XO Lite
This month, a huge rework was done to get a better management of collections and events. This will be also very helpful for XO 6. The experience we get on XO Lite is really important to be able to develop a solution at scale for thousand hosts.
If you are interesting into the coding details, enjoy the read!
New iteration for XenApi records stores and collections
Long story short, we are revamping the way XenApi functions, introducing an event-based system for more streamlined data handling and better performance, all while simplifying the coding experience through new helpers and a cleaner organizational structure.
XenApi
Rather significant change in the way XenApi works. Previously, you had to call injectWatchEvent, registerWatchCallback and startWatch. On connection, we would load all existing types from the server. Every second or so, we would call event.from for all previously loaded types.
Then, for each result returned, the previously defined callback method was called, with the result as a parameter. It was then up to this callback to handle each result, check its type, find the corresponding store and insert/update/delete the record, etc.
This had several drawbacks:
- All types had to be loaded at startup
- We had to call
event.fromwith all types every second - We had to check the type of each result in the callback to see if it was supported
- We had to find the corresponding collection in the callback
- We had to check whether a component had subscribed to this collection
- The callback had to insert/update/delete the record in the collection.
Instead, we decided to bring up an event system within XenApi! It's now up to each store to add listeners to the events it's interested in. These events are named <type>.add, <type>.mod and <type>.del. For example, as soon as there is at least 1 subscription to the messageStore, it will call xenApi.addEventListener for the message.add, message.mod and message.del events.
Now, every second or so, a call is made to event.from with only the list of types for which at least one event has been registered. Consequently, if components on a page have subscribed to the vm and host stores only, then the call to to event.from will only be made for these two types. And callbacks will be called accordingly. If a VM has been deleted, only the callbacks registered for the the vm.del event (if any) will be executed and the store itself will update its own collection.
Finally, as soon as there are no more subscriptions, the store will remove these callbacks via xenApi.removeEventListener.
Stores & Collections
These new modifications also bring back the store usage to handle XenApi collections: it uses a kind of a mix of the solutions used in previous iterations. The problem with the exclusive use of composables was that the collection extension was executed on every call. So if 10 components call useVmCollection, then anything added to the base collection (addition of computed, functions, etc.) is repeated 10 times.
Using a store solves this problem, as the store setup function is only executed once. The problem with using a store is that it has no way of knowing how many times it has been used. It is therefore impossible to automatically subscribe, or to pass parameters to useVmStore() (for deferring for example).
A basic store is therefore created as follows:
export const useVmStore = defineStore('vm', () => createXenApiStore("vm"));If you want to extend this store with additional data, it's very simple:
export const useVmStore = defineStore('vm', () => { const baseStore = createXenApiStore("vm"); return { ...baseStore, recordsCount: computed(() => baseStore.records.value.length) }});But as I was saying, it's not possible to do a subscribe automatically.
You'd have to manage the subscription manually, and also end up with all the store properties, most of which are not useful.
// To be done every time you want to use a store... const vmStore = useVmStore();const { records } = storeToRefs(vmStore); const id = Symbol(); onBeforeMount(() => vmStore.subscribe(id)); onUnmounted(() => vmStore.unsubscribe(id)); // vmStore.<cursor> <- autocomplete with all store properties ($onAction, $subscribe, $state, _customProperties etc.)This is where a new helper comes into play: createSubscriber. It will return a function which when called will take care of creating the id, subscribing, performing the onUnmount and managing the defer option, which allows you not to fetch data immediately. It will also filter out any store "noise" and perform the storeToRefs automatically.
// vm.store.tsconst useVmStore = defineStore("vm", /* store setup */) const useVmCollection = createSubscriber(useVmStore);This greatly simplifies usage:
const { records } = useVmCollection();// ^-- Here, only useful properties (records, hasError, etc.) are proposed to completion.Code reorganization
XenApi code has been split to 3 files:
libs/xen-api/xen-api.ts: contains theXenApiclasslibs/xen-api/xen-api.type.ts: contains all the typingslibs/xen-api/xen-api.utils.ts: contains helpers, enums etc.
This XenApi could one day be published in its own package, so:
- Any code concerning the
XenApimust be in thelibs/xen-apidirectory. - Any code used by any file in the
libs/xen-apimust not be aware of any other part of the XOL project.
Pool dashboard: Alarms (load on demand)
We added a component in XO Lite: the list of alarms message coming from your host. Initially, we loaded everything, but you can have more than thousands alerts. This has a big tool on the initial loading of the main dashboard. That's why we dedided -this time- to only load them on demand.

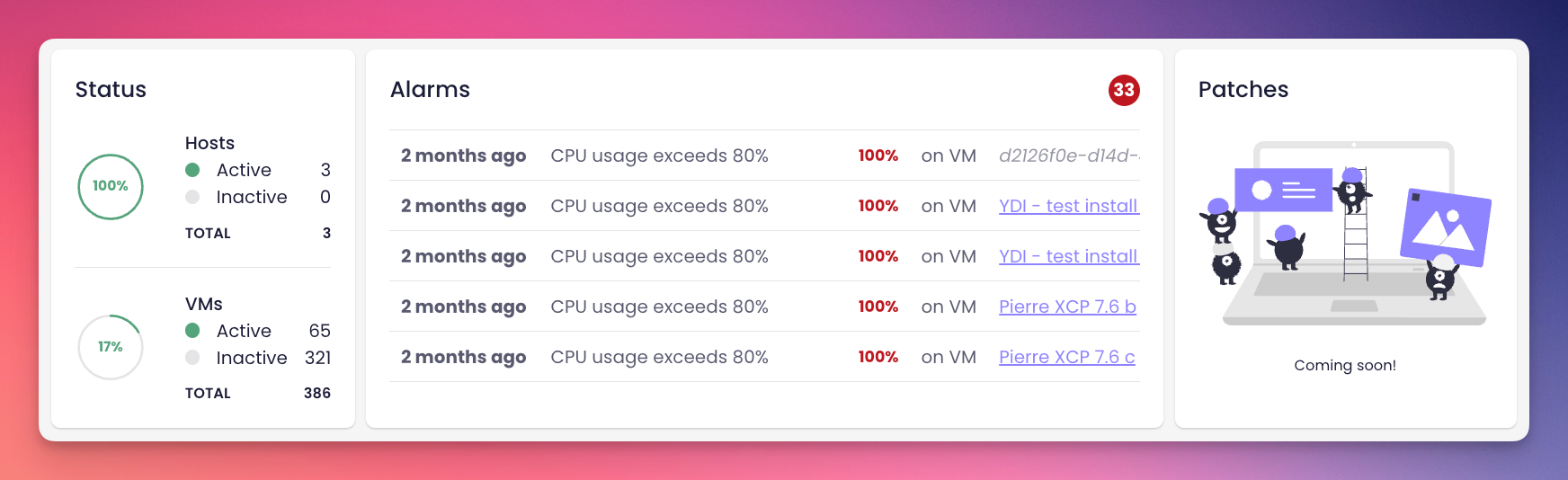
🗃️ XOSTOR Preview
XOSTOR's core functionalities have reached a level of maturity suitable for production use across various infrastructures. Our current focus is on refining the User Interface, and we're pleased to report significant advancements in this area.
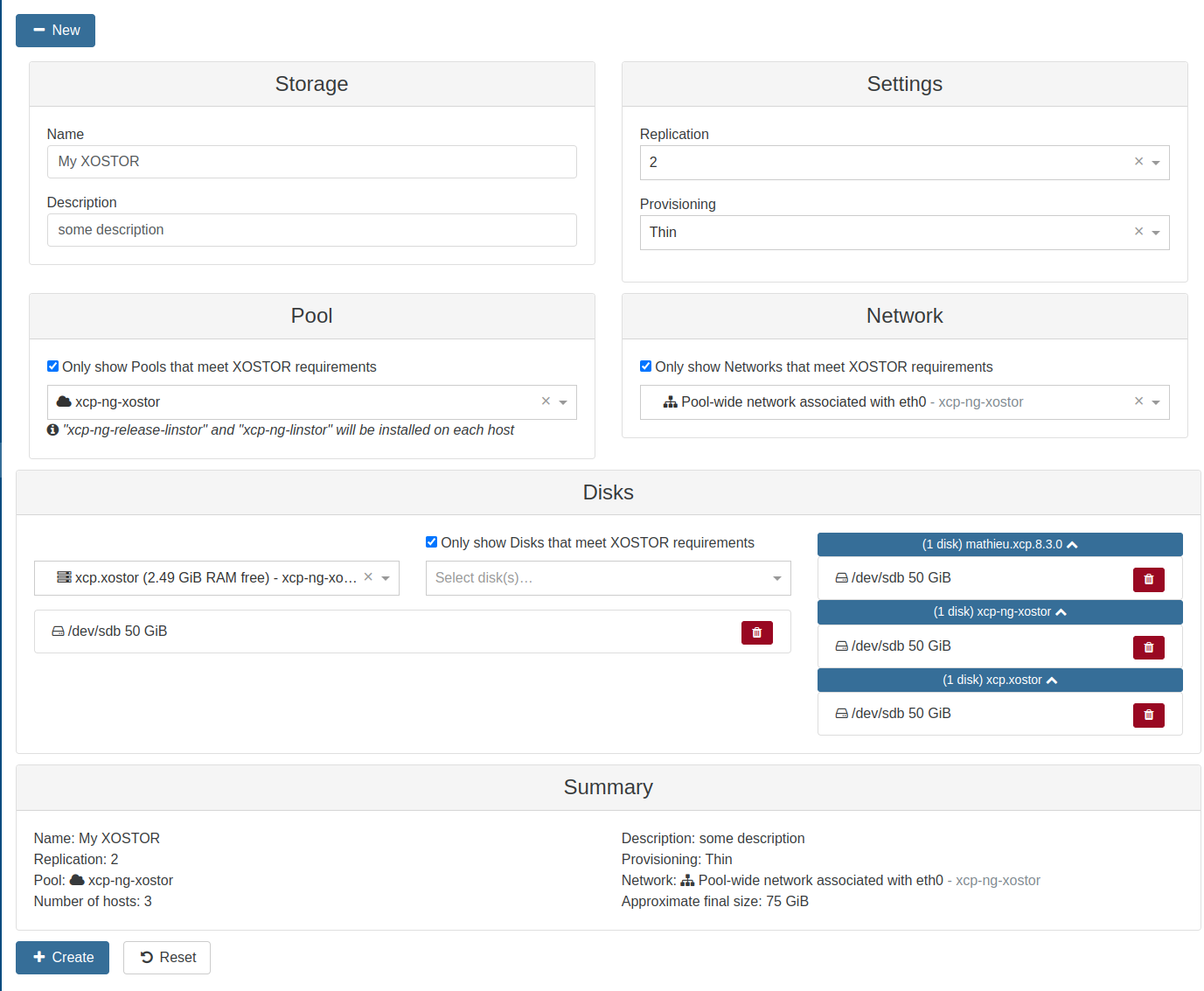
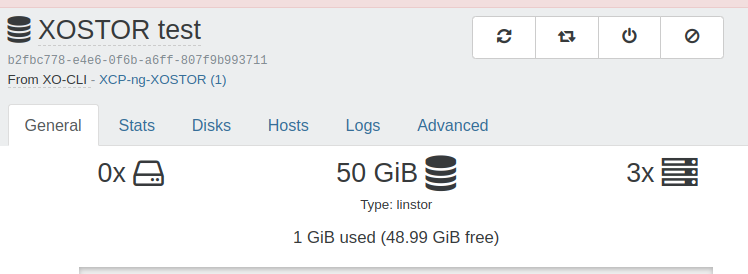
This means we entered the home straight before releasing it officially! This UI is only available on a specific branch right now, but expect to be available directly in XOA for our next release!
🆕 Misc
There's also various improvements done during this month of August.
Possibility to configure crash_dump_SR
A crash dump SR is a place when you can store the memory dump of a crashed VM. It might be helpful to use when your guest OS is crashing and you want to understand why.
While configuring a crash_dump_SR via XO CLI was feasible, we've streamlined the process to offer a more user-friendly approach:

Expose use NBD settings on backup jobs
We added a setting in the advanced tab of incremental backup to allow users to set NBD setting directly from the UI:
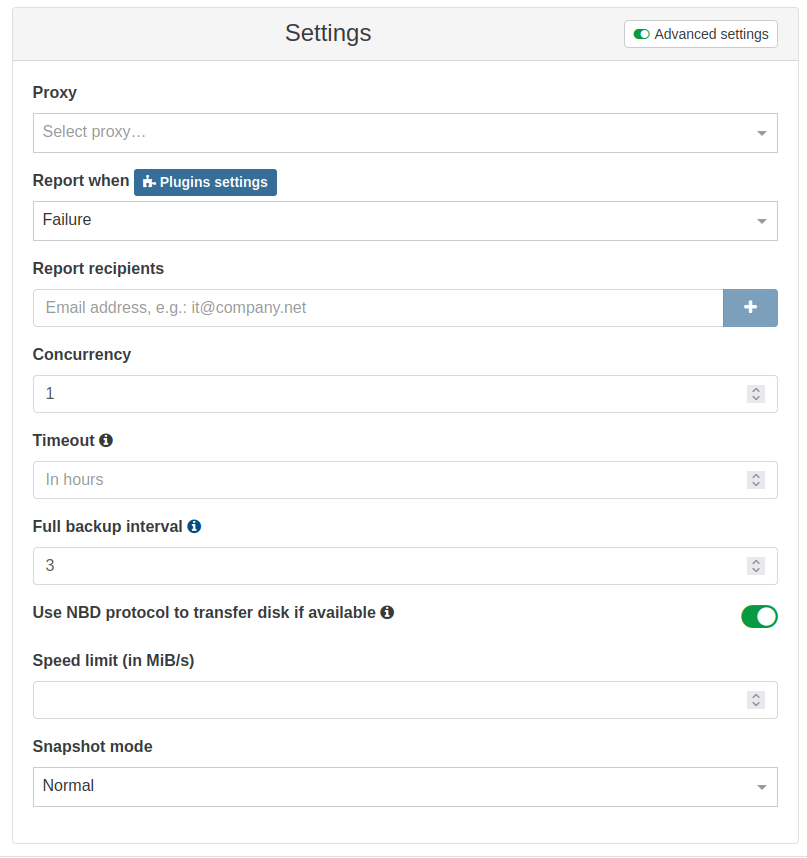
As a reminder, NBD-enabled backup are in general faster than the traditional VHD handler, generated by the XAPI.