SaltStack CVE-2020-11651 and CVE-2020-11652 incident
Coin mining script ran on some of our VMs for few hours, and we were lucky nothing bad happened to us: no file affect nor any data breach. Read the full story!


Sunday night, we were hit by an attack that was caused by 2 SaltStack vulnerabilities[1], also affecting the rest of the world[2]. We are sharing transparently with you exactly what happened and how it affected us.
TL;DR: A coin mining script ran on some of our VMs, and we were lucky nothing bad happened to us: no RPMs affected and no evidence that private customer data, passwords or other information has been compromised. GPG signing keys were not on any affected VMs. We don't store any credit card information nor plain text credentials (securely hashed with argon2+salt). Lesson learned.
What happened: detailed timing
Note: timing is in UTC.
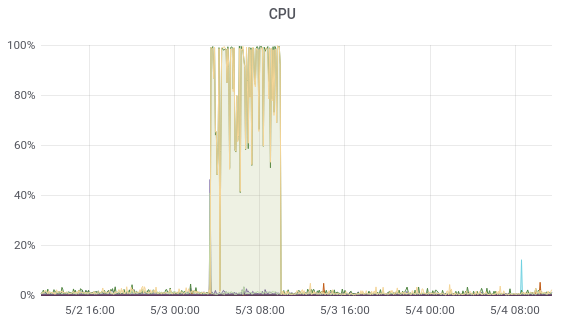
- At 1:18AM, Sunday, May 3: some services on our infrastructure were unreachable. Only a subset of them, but almost at the same time on various virtual machines in various datacenters. High CPU usage was also another visible symptom.
- At 7:30AM, the same day: Olivier noticed the outage on some services. Immediately affected VMs were rebooted, and all services came back. However, feeling that something was wrong, a full investigation started. Only a dev machine was kept "as-is" after reboot, all others were investigated and some non-essential services disabled. At this time, we already knew precisely which VMs and services were affected. Firewalls were re-enabled after being "mysteriously" disabled.
- At 11:30AM, the dev machine was displaying the same previous symptom again. But now, it was visible live. The culprit was identified quickly as a "rogue" Salt Minion process mining coins (hence the CPU usage, a process that also stopped web servers). It didn't happen again on other VMs because Salt Minion was disabled on them. This is when we understood SaltStack CVE-2020-11651 and CVE-2020-11652 were the attack vector.
- From there, more targeted investigations started about the payload. These investigations lasted all Sunday (and part of the night), to see if something else happened outside the "basic attack". Using VM backups from Xen Orchestra, we were able to check/diff entire filesystems before, during and after the attack. It helped us to be confident about which payload version affected us and that nothing else was involved.
- No other sign of the attack since then, with close monitoring of all VMs metrics. That's also why we knew exactly what happened.
 |
|---|
| Whole attack duration is very visible from VM metrics |
At this stage, it was clear we were caught in a broad attack affecting tons of people. We believe the initial assessment that "thousand of infrastructures targeted" might be an understatement [3]. Good news in this case, was the very generic payload, built probably really quickly to generate money fast without being stealthy.
Note: no XCP-ng hosts were attacked because we don't use SaltStack on them!
Payload analysis
Because of the attack behavior, we were able to analyze the payload. The version of salt-store in cause was "V1", with the following md5sum: 8ec3385e20d6d9a88bc95831783beaeb. Luckily, this payload version is pretty basic:
- disable all firewalls
- disable some CPU intensive processes (NGINX, Apache, etc.)
- tune your system for more efficient mining
- mine coins

Also, Version 1 is not persistent: it comes from the SaltStack vulnerability, but doesn't survive a reboot (matching the behavior of what happened to us). However, we double checked all crontabs because further versions later added persistence. Also, no suspicious network activity was seen during the attack: because all webservers went down, there was almost no extra traffic on the affected VMs and it helped to see what's going on.
A big thanks to the SaltStack community who shared all the details together, helped us to go faster and crowdsource all the results and analysis! Read more there: https://github.com/saltstack/salt/issues/57057 and here https://saltstackcommunity.slack.com/archives/C01354HKHMJ/p1588535319018000
Why we were vulnerable
SaltStack is used to push updates or configure multiple VMs at once. We trusted its communication protocol (using keys) and we used that flexibility to add new VMs dynamically, without using a VPN or a secure tunnel. This was a mistake: it allowed the attackers to access the available Saltmaster port to inject their payload in available minions.
Also, a salt master patch wasn't available in our master distro repository before the attack. We were just unaware of this coming. It's on us, and it's a good lesson.
On the good side
- Our most important stuff is hosted in Git repositories: it's trivial to validate nothing was changed on our internal applications
- We are happy to trust an external Credit Card provider (Stripe) so we don't have to deal with any credit card data
- We also don't have any plain text credentials (securely hashed with argon2+salt)
- XO Backups were really useful to compare what happened before, during and after
- We could validate that no Xen Orchestra package was affected nor modified
- XCP-ng RPMs repository were not touched. Even if they had been altered, it would not have been able to affect our user's hosts thanks to metadata and RPMs GPG signing.
- XCP-ng GPG signing key is safe: the signing server wasn't affected by the attack
Actions
Assessing the damages (luckily none) was the first step. We are aware it might have been far more dangerous, so we took a set of measures to increase our level of protection:
- SaltStack won't be used anymore, at least in the short term. Master node is off, and Salt minions were removed on all VMs. Due to the relatively small infrastructure size, we decided it's not essential for our operations.
- We are changing all system passwords anyway, and also all token/keys with external services.
- Management network is being revamped to be entirely private (using VPNs/tunnels)
- Having our platforms in various DCs at various bare-metal providers was also a cause of not using a private network: it's less convenient. We already had plans to host our infrastructure ourselves, using the same racks used for our https://xcp-ng.com/cloud. We'll accelerate our plans.
- We continue to closely monitor VM activity: new alerts were created that matches payload behavior (CPU usage). So far, so good.
- We continue to assess all our systems in case we missed something, by participating with the SaltStack community, also helping people affected.
- We communicate (here!) regarding what happened.
- We are improving our alert system to react more quickly in case of incidents on our own infrastructure. Weirdly enough, we are more reactive for customer issues on their premises than for our own machines.

Conclusion
In short, we were caught in a storm affecting a lot of people. We all have something in common: we underestimated the risk of having the Salt Master accessible from outside.
Luckily, the initial attack payload was really dumb and not dangerous. We are aware it might have been far more dangerous and we take it seriously as a big warning. The malware world is evolving really fast: having an auto update for our management software wasn't enough! The attack came before any update was available in our SaltMaster Linux distribution.
Lesson learned: we are hardening everything, creating a dedicated management network, only exposing what's needed. We'll provide guides to harden your own XCP-ng/Citrix Hypervisor infrastructure, from what we've learned here.
If you are running SaltStack in your own infrastructure, please be very careful. Newer payloads could be far more dangerous. You can follow the Salt GitHub issue about what's going on!
https://labs.f-secure.com/advisories/saltstack-authorization-bypass ↩︎
https://www.ibtimes.sg/hackers-take-down-googles-android-substitute-lineageos-server-ghost-blogging-platform-44314 ↩︎
"A scan revealed over 6,000 instances of this service exposed to the public Internet" F-Secure ↩︎