Improving Xen Orchestra performances

This blog post is about how we made a leap ahead in performances for the next incoming release. It should be interesting for everyone, probably because this story will happened (or already happened) to you if you are developing software. And especially using an external API.
Spoiler alert, here is a preview of our results, current stable 4.1 VS next release 4.2 (lower is better):
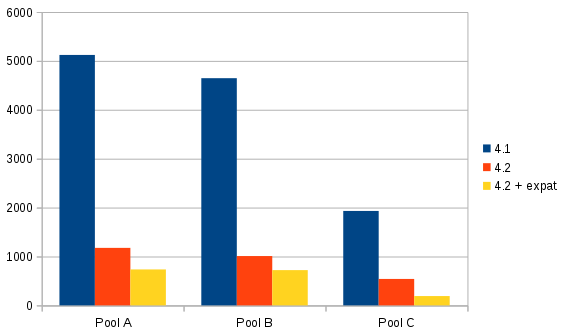
- X axis: 3 pools where our tests are made
- Y axis: total time (in ms) to get all objects in a Pool
Pool A is bigger than Pool B (more hosts/VMs), which is bigger than Pool C.
But this is only a small fraction of the performance boost, because bigger is your infrastructure, higher is the impact!
Find the bottleneck
We are using the simple but extremely useful blocked module to detect when the Node event loop is blocked.
You can spot the related logs called xo:perf in the following trace:
> node bin/xo-server
app-conf /home/user/.config/xo-server/config.yaml
xo:main Configuration loaded.
xo:main Web server listening on http://0.0.0.0:9000
xo:main Setting up / → ../xo-web/dist
xen-api root@192.168.1.1: session.login_with_password(...)
xen-api root@192.168.1.1: connected
xen-api root@192.168.1.1: event.from(...)
xo:perf blocked for 3419ms
xo:perf blocked for 2768ms
xo:perf blocked for 9824ms
XML parsing is costly
Thanks to this logs, we were able to see that the performance issues were related the reception of XAPI (XenServer API) messages. After some more analysis, we could tell it was due to the XML parsing of this messages.
To understand why we are decoding XML, let's review our current architecture:

XML-RPC is currently the way to talk to the XAPI. When you are connected to one pool, you got XML content to decode to get all objects in it. That's OK, until you are connected to a TON of other pools: Xen Orchestra have to parse a LOT of XML. And parsing XML is very CPU intensive because XML is a huge crap very powerful.
So, we got multiple leads to improve it:
- decode the XML faster thanks to Expat
- find a way to have less XML to parse
- use a dedicated worker for this task
- throttling events
Each solution have drawbacks, so we needed to carefully measure the performance impact to make wise choices.
Create a dedicated issue
We choose to create an issue related to this problem. And because Xen Orchestra is modularized, we just had to work in a specific library, without modifying xo-server itself. The issue regroups all our performances tests, with branches for each experiment.
This way, we can make benchmarks properly, by just switching branches.
Parse faster
Our first initiative was to try Expat. It parses XML faster than our previous lib.
Initial results were encouraging: 3 to 4 times faster! But the progress is constant: more servers/pools you had, it "stays" 3 to 4 times faster. That's because the XML quantity is proportional to the objects number (pools, servers, VMs, etc.)
The serious drawback is the library itself: because it's written in C, it had to be built on each system we have deployed. This is a risk when you don't have control of where your software is executed (i.e: inside the client company, XO is not in SaaS!)

Parsing faster is like using a sports car to make a race: you are going indeed faster than your regular car, but it's complicated to build (and to maintain).
So we searched another way to be faster...
Less XML
Okay, so XML parsing is CPU intensive. Why not having simply less XML to parse? We asked the XAPI team if there is a way to do so.
And... there is! We have the possibility to use JSON encapsulated in XML-RPC. It means, roughly: a bit of XML, and inside a data tag with everything we needed in JSON.
This is a very good news because:
- it scales very well: bigger the infrastructure, better it boosts the performances. Indeed, we'll have more data (JSON) for same quantity of XML (so less XML for same data)
- it's in the XAPI since a long time (more than 3 years)
- we tested it quickly and the results were very good
Good how? 4 times better in our very small lab. More than 4 times on a bigger infrastructure. Will our theory be correct? See the conclusion ;)

Less XML is equivalent to have the finish line closer to you. You don't have to go faster if you have (a lot) less to travel.
Remove all XML?
The perfect solution: XAPI should be able of talking JSON-RPC only... But this is not yet possible in XenServer! The next release of XenServer (7?) will probably have this, new tests will come soon.
This is an ideal world for us: no more XML! We'll test it as soon as possible :)

Throttling events
Thanks to the XAPI event system, we have the possibility to delay some of them, to avoid a kind of "fragmentation" (a lot of small XML files with JSON in it). By throttling events, we could have bigger files, thus reducing the XML parsing cost. And also have less HTTP requests!
The drawback is to sacrifice a small delay (i.e: less reactive system). This is only an idea so far, we didn't make any test yet. But still, we got a promising lead.
Going deeper

More than "pure" performance, there is also another thing we can do. As you may know, Node is single threaded. But that's not true if we use workers!
Workers
Basically (and roughly), we can delegate something to a worker. It takes an input and gave us back an output. It's pretty basic, but we can imagine to delegate some intensives tasks to it (like... XML parsing?), and so exploiting multi-core capabilities without slowing the main event loop.
But... this needs a non-negligible amount of work to be done carefully and properly. This lead will be probably explored in the next months.

Final choices and results
So we decided to be "conservative" in a first place, by using only encapsulated JSON in XML-RPC. This offers, without taking too much risks, a 4 times faster Xen Orchestra on our small infrastructure. Expat parser gives a small boost, but not enough facing the risks in production/deployment.
- X axis: 3 pools where we make our tests
- Y axis: total time (in ms) to get all objects in a Pool
And how about a big infrastructure? Like this one:

Our initial calculations indicate roughly something around 250 times faster. That is a huge leap! Stay tuned for the 4.2 coming this week.